我们网站从很多年一直使用国外的开源平台MediaWiki和Drupal,都是用的UTF-8字符集来支持多语言,URL网址也是采用的系统自带或者插件自带的编码方式,例如:查号吧网站里面有个标题为“越南”页面,URL网址不是“https://www.chahaoba.com/越南”,而是UTF-8编码后的“https://www.chahaoba.com/%E8%B6%8A%E5%8D%97”,这在Google里面、百度里面搜索和展示也都没有问题,用户用各种浏览器打开也都正常。
但我们发现在百度快照中却有问题,截图如下:
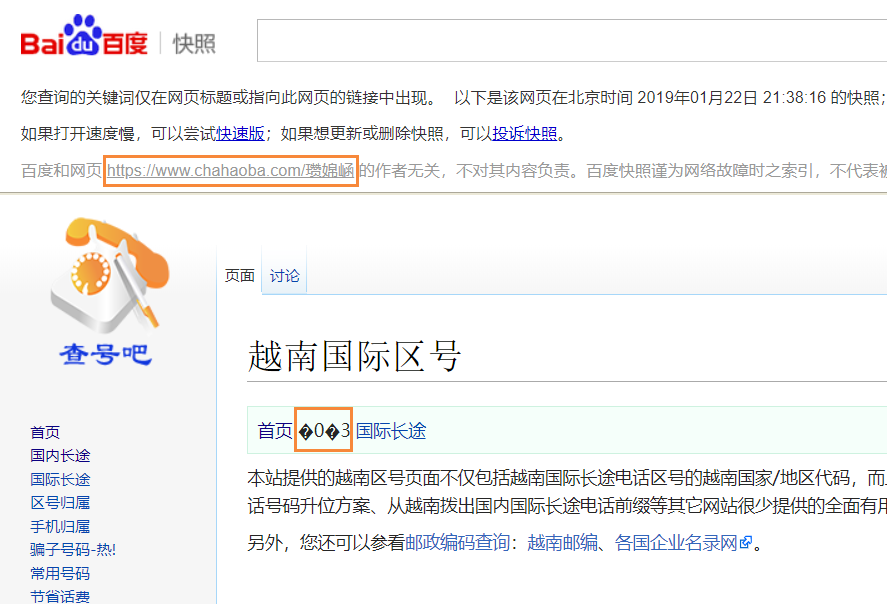
可以看到其中有两个地方出现乱码,一个是我们的网页网址中的“瓒婂崡”乱码,一个是我们页面中面包屑导航用到的“»”字符。
在浏览器中查看百度快照的源代码,发现快照页面本身采用的编码是GB2312:
<!DOCTYPE HTML> <!--STATUS OK--> <meta http-equiv="Content-Type" content="text/html;charset=gb2312"> <base href="https://www.chahaoba.com/瓒婂崡"> ... <div id="bd_snap_note">百度和网页 <a href="https://www.chahaoba.com/瓒婂崡">https://www.chahaoba.com/瓒婂崡</a> 的作者无关,不对其内容负责。百度快照谨为网络故障时之索引,不代表被搜索网站的即时页面。</div> ... <div style="position:relative"> <!DOCTYPE html> <html lang="zh-CN" dir="ltr" class="client-nojs"> <head> <meta charset="UTF-8"/> <title>越南国际区号 | 查号吧</title> ... <span itemprop="itemListElement" itemscope itemtype="http://schema.org/ListItem"> <a itemprop="item" href="/%E9%A6%96%E9%A1%B5"> <span itemprop="name">首页</span></a> <meta itemprop="position" content="1" /> </span> �0�3 <span itemprop="itemListElement" itemscope itemtype="http://schema.org/ListItem"> <a itemprop="item" href="/%E5%9B%BD%E9%99%85%E9%95%BF%E9%80%94"> <span itemprop="name">国际长途</span></a> <meta itemprop="position" content="2" /> </span> ... </body> <!-- Cached/compressed 20190121051958 --> </html> </div>
从上面可以看出百度快照页面本身用的是GB2312编码,那么它包含进去的我们的页面中“»”字符是不在GB2312编码内的,就显示成乱码了。
另外,百度快照对我们网页的URL中的UTF-8编码成的“%E8%B6%8A%E5%8D%97”误认为是GB2312编码,本来是两个汉字对应的“%E8%B6%8A”和“%E5%8D%97”,被划分为“%E8%B6”、“%8A%E5”、“%8D%97”三个汉字的GB2312编码,对应成了错误的三个中文字“瓒婂崡 ”,这三个中文字网址“https://www.chahaoba.com/瓒婂崡”再使用正确的UTF-8编码后网址变成了“https://www.chahaoba.com/%E7%93%92%E5%A9%82%E5%B4%A1”,在我们网站中页面就打不开了。
而百度搜索结果页本身就是使用的UTF-8编码,所以不存在上面说的这样的问题。只是百度快照页面使用的技术太老旧,charset还是gb2312或者big5,且没有改用https。
知道这个原因后,我们其实是可以做反向转换、编码,找到正确的网址的,后续工作以后再记录。甚至可以考虑做一个专门的乱码对应正确字符的网站出来。
参考工具:乱码恢复
另外,最近还发现百度MIP也出现一些奇怪的错误,例如搜索结果页是正确的,但点击后到达一个错误的页面,还待排查。后来已经解决,清理了MIP缓存,详见:《清除百度MIP缓存,纠正跳转错误》。
2019年2月补充:春节期间搭建了我们自己的乱码还原网站,也可以说是乱码纠正词典,因为导入了几十万个中文字词并列出了各种编码组合,希望对大家有用。
评论6
编码GB2312确定是按照你说的改么?
编码GB2312确定是按照你说的改么?嗯,我基本上都是可以确认上面写的内容
嗯,我基本上都是可以确认上面写的内容。但你说的改我不知道是指的改什么?改自己网站的编码还是什么?
博主你好,刚刚阅读完这篇文章发现确实是这样的
博主你好,刚刚阅读完这篇文章发现确实是这样的,由于百度快照的源代码编码格式是GB2312,所以大多数国内编码格式为UTF8的网站在百度快照中或多或少都会有一些字符产生乱码,而我刚刚查看了一下我博客在谷歌快照,发现并没有产生乱码,而谷歌快照源代码的编码格式为UTF8,也证实以上博主帖子的观点!谢谢!是的,Google快照不存在这种乱码问题。
是的,Google快照不存在这种乱码问题。
希望博主可以考虑在评论中加上填写邮件这个功能
希望博主可以考虑在评论中加上填写邮件这个功能,因为相信大多数的评论者都会希望自己的留言能够得到博主的回复,而邮件正好可以通知评论者该评论已经被回复,只是个人的建议,希望可以考虑一下!谢谢阿南的留言和建议。以前默认是开启留言用户填写联系方式的
谢谢阿南的留言和建议。以前默认是开启留言用户填写联系方式的,后来太多发垃圾链接、宣传链接的,我就关闭了用户留言,现在重新打开了。