
Emoji的结构比想象的要复杂一些,一个简单的要求是从一段包含Emoji表情符号的文本中提取出Emoji,我以前的做法是拿几千个Emoji按照从长到短排序后循环比对,这样基本上可以实现需求,不过运算量很大,在单个Emoji的HTML页面中循环几千次的耗时还是可以忍受的(与数据库读写时间的零点几到几毫秒、网络传输时间的几十到几百毫秒比起来,PHP或者Python
Emoji的结构比想象的要复杂一些,一个简单的要求是从一段包含Emoji表情符号的文本中提取出Emoji,我以前的做法是拿几千个Emoji按照从长到短排序后循环比对,这样基本上可以实现需求,不过运算量很大,在单个Emoji的HTML页面中循环几千次的耗时还是可以忍受的(与数据库读写时间的零点几到几毫秒、网络传输时间的几十到几百毫秒比起来,PHP或者Python
我们公司以前办理高新技术企业的时候就申报过很多项计算机软件著作权登记,做EmojiAll.com这个网站的时候我们很重视,不仅申办软件著作权,还申请了作品版权来保护写作的Emoji描述解释、应用举例等原创内容。
高新技术企业对软件著作权的数量有要求,可以每年申请多个,我们本来对Emoji网站也进行了更新,刚拿到的登记证书中些的V2.0。
我们从2019年初开始用PHP绘图功能在网站上输出图片,我们在邮编库网站上添加了信封例子图片如下:

这可以让用户更直观看到如何填写邮政编码,在其它一些网站上也看到过用户复制引用我们的信封例子图片。
不过我们发现还有不少用户提出“邮政编码每位数字代表什么含义”的问题,可见有这种好奇心的人也不少,那我们就来满足你们
今年2月份我们就在EmojiAll网站上推出了Emoji关系图,为每一个Emoji展示与其有关的其它Emoji。如果是人工来为每一个Emoji添加与其有关的其它Emoji将是一个很费力的事情,因此我们当时也使用了一些算法来解决,从多个数据源、不同的角度来分析出相关Emoji及远近关系,在展示的时候也适当添加了第二级、第三级的关系,如下图:


去年上半年我们进行了Emoji 13.0内容的更新和添加,而下半年更新和添加Emoji 13.1版本内容,我们往往都拖后了一段时间,几个月后才进行补充和更新,而这次Unicode 14.0和Emoji 14.0的发布时间是在推出前我们就了解到的,并提前做了准备工作
我们邮编库网站提供邮政编码查询的服务有20多年历史了,真的是比所有其它邮编查询网站提供的时间更长、也更专注,这么多年一直不断在这个小小的领域默默改进。即使现在邮政编码的使用频率越来越低,查询邮编的人比以前少了很多,我们却反而推出任意地址邮编查询、微信公众号改进、用IP地址或者手机定位获取用户位置及邮政编码,今年还推出大的改版更新。
很多年前看到百度中搜索邮政编码会出现直接结果,标注来自邮政官方某机构,这种方式当时叫着百度的阿拉丁计划,我们也曾经想去申请,但似乎门槛很高,就没有花力气联系。
今年初接到百度相关人员的联系,主动询问我们是否愿意参加这种合

去年2月份我们更新和添加Emoji 13.0内容,11月份我们更新和添加Emoji 13.1内容,并且添加Emoji v13.0和v13.1的图片。添加后的版本可以在我们EmojiAll网站上查看:Emoji版本13.0,Emoji版本13.1。
而E
早在今年2月份,我们的EmojiAll网站就推出了Emoji标签云,从数据的处理到展示的形式还是非常新颖的,我们自己觉得很有特色。这其中用到了统计分析软件,对来自twitter的推文内容进行了处理,为几乎每一个Emoji找出对应的标签,以免人工来写标签工作量太大,另外再辅以其它的数据来源和处理,综合形成当时的数据。
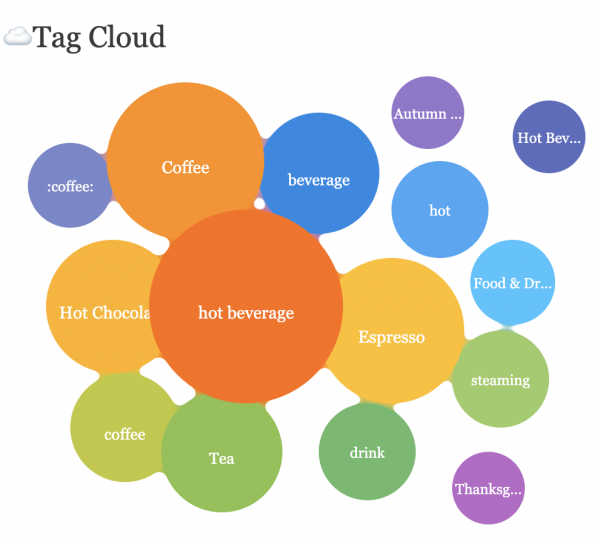
但我记得当时软件从推文中进行统

前阵子发现一个网站(www.emojitip.com)复制了我们网站(www.emojiall.com)的原创内容,我们要求Google删除侵权网站的收录,G
今年5月份记录了一篇《Emoji动画图片》,当时就只找到了JoyPixels的Emoji动画图片,举的例子是“🎻 小提琴”的图片:

后来的一段时间陆陆续续又找到了一些动画Emji,现在记录下来:
Telegram提供的动画Emoji图片,其特点是GIF的帧数比较高,虽然文件比较大,但动画看起来也更顺畅自然,例如“🤌
2002-2023 v11.7 a-j-e-0