早在今年2月份,我們的EmojiAll網站就推出了Emoji标簽雲,從數據的處理到展示的形式還是非常新穎的,我們自己覺得很有特色。這其中用到了統計分析軟件,對來自twitter的推文内容進行了處理,為幾乎每一個Emoji找出對應的标簽,以免人工來寫标簽工作量太大,另外再輔以其它的數據來源和處理,綜合形成當時的數據。
但我記得當時軟件從推文中進行統計分析得出來的數據質量并不算好,有不少都看上去有明顯問題,與人工來添加标簽相比的話,質量還是差很多,因此當時對與這批軟件自動處理出來的标簽數據我們并沒有完全采用,而是隻采用了一部分,混合其它多個數據來源做成的實際展示标簽數據。
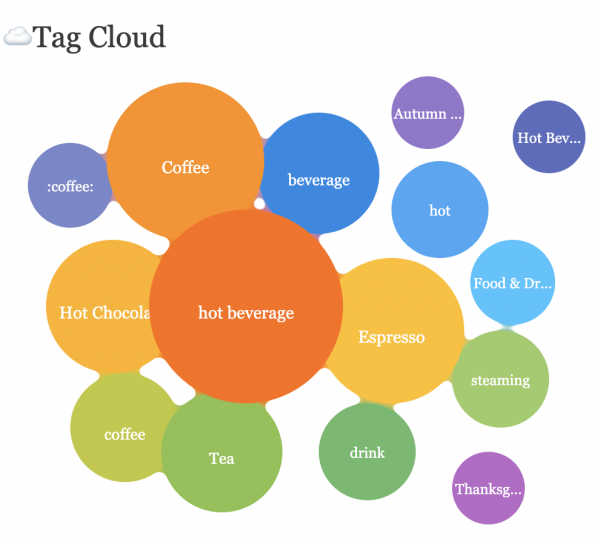
時隔半年以後,我們獲取到了更大量的twitter曆史數據,我們數據分析的同事技術水平有了較大提升,把學習到的機器學習等技術可以運用到新一輪的處理中,處理出來的數據質量明顯提升,下面是我用"面包 Emoji 🍞"為例子做的一個對比:
|
新處理出來的數據 "bread" |
以前處理出來的數據 "bread" |
以前處理的數據中無關的英文詞看上去太多,而新處理的就關聯性高了很多。當然這離不開算法上的改進,以前隻是比較簡單的數學統計,新的處理中運用了機器學習方面的技術,采用一些相對比較成熟的自然語言處理模型,再根據實際情況制定合理的處理流程,如下圖:
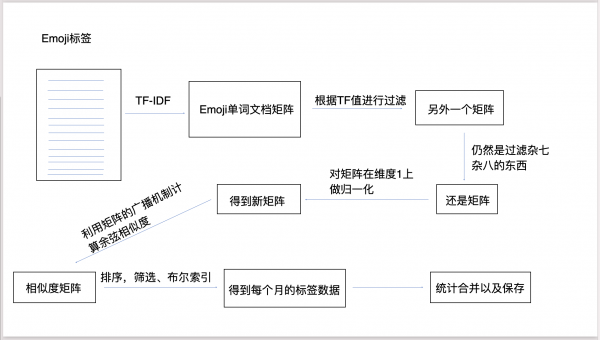
這次處理的數據量也比以前大很多倍,從而能保證得出結論的準确性更高,而更大的數據量和更複雜的AI算法也意味着比以前大得多的計算量,剛開始用開發的筆記本電腦算起來太慢,我們又拿出單獨的台式機日夜運算,以及把數據分布在多台機器上獨立處理然後再合并,還嘗試購買阿裡雲上的專門AI資源幫助加快處理。還要在軟件上采取各種方式來優化提升速度,這樣一種語言的處理也需要好多天時間來計算。
除了英文以外,我們對日文等其它語言也進行了标簽的計算,我們懂日文的同事檢查過,說這些機器打上的日文标簽還是具有很高相關度的,再針對日文中的平假名、片假名進行一定的權重調整後效果還是很不錯的👍
下面還是拿面包Emoji🍞為例,從日語的推文中處理出來的日文标簽及權重值如下:
["パン", 0.3156] ["トースト", 0.0502] ["モカ", 0.0442] ["セール", 0.0225] ["美玲", 0.0222] ["佐々木", 0.0218] ["チーズ", 0.0211] ["パンツ", 0.0185] ["朝食", 0.0147] ["日向", 0.0128] ["メロン", 0.0112] ["ぱん", 0.011] ["キャンペーン", 0.0109] ["モーニング", 0.0102] ["ツイート", 0.0097] ["バター", 0.0095] ["発売", 0.009] ["フォロー", 0.0086] ["サンド", 0.0085] ["クリーム", 0.008] ["朝ごはん", 0.0074] ["プレゼント", 0.0072] ["食べ", 0.007] ["カレー", 0.0068] ["いー", 0.0065] ["祭り", 0.0048] ["とけ", 0.0047] ["なっ", 0.0045] ["本日", 0.0045] ["美味しい", 0.0044] ["お腹", 0.0037] ["ちゃん", 0.0037] ["おいしい", 0.0036] ["最高", 0.0036] ["限定", 0.0035] ["食べる", 0.0035] ["最近", 0.0033] ["質問", 0.0033] ["ない", 0.0033] ["おはよう", 0.0033] ["たい", 0.0031] ["明日", 0.003] ["寫真", 0.0029] ["好き", 0.0029] ["たっぷり", 0.0028] ["美味し", 0.0027] ["買っ", 0.0027] ["昨日", 0.0025] ["する", 0.0025] ["ください", 0.0021] ["ご飯", 0.0021] ["作っ", 0.002] ["まで", 0.002] ["作り", 0.002] ["ぜひ", 0.0019] ["入り", 0.0019] ["けど", 0.0018] ["大好き", 0.0017] ["たら", 0.0017] ["こと", 0.0017] ["そう", 0.0017] ["これ", 0.0017] ["より", 0.0016] ["ある", 0.0016] ["ありがとう", 0.0016] ["なる", 0.0014] ["時間", 0.0014] ["いい", 0.0014] ["くん", 0.0013] ["くれ", 0.0012] ["よう", 0.0012] ["思っ", 0.0011] ["だっ", 0.0011] ["でし", 0.0011] ["あり", 0.0011] ["いる", 0.0011] ["なく", 0.0011] ["いつ", 0.001] ["なり", 0.001] ["行っ", 0.001] ["もう", 0.001] ["いう", 0.001] ["楽しみ", 0.001] ["願い", 0.001] ["なん", 0.0009] ["よろしく", 0.0009] ["だけ", 0.0009] ["良い", 0.0009] ["みんな", 0.0009] ["めでとう", 0.0008] ["やっ", 0.0007] ["すぎ", 0.0007] ["ませ", 0.0007]
我看不懂日文,但用Google翻譯粗略看過,還是不錯的,日文專業的同事也認可了這些标簽的質量,超出了預期。
既然英文和日文的處理都沒有問題,我們以後還會計算更多其它語言的标簽出來,并且把這些數據在多個方面進行使用。✌️
2021年9月補充:Emoji關系圖中運用人工智能進行升級
评论