
AI批量生成的圖片質量大部分過得去,但也有一小部分不能符合要求,比較經過檢查才行,而人工檢查成千上萬的圖片非常耗時,最近我們使用AI來進行自動化質量檢查,雖然最後的結論是目前還無法用自動檢查替代人工檢查,但中間也有不少收獲,下面記錄一下過程和要點,也可以供其他有類似需求的朋友參考。🤝
一、問題提出
為網頁繪制配圖一直是我想做的事情,AI繪圖以前需要人工來繪制插圖,工作量和成本不可想象,現在AI繪圖出現後就有了為大量網頁繪制插圖實現的可能。
我們從去年上半年就摸索Stable Diffusion生成圖片,後來購買Midjourney賬号使用,再後來ChatGPT+DALL-E 3來繪圖,先嘗試手工操作處理,再後來嘗試批量生成圖片。
生成成千上萬圖片後需要人工檢查,費時費力,成了阻礙我們繼續使用文生圖模型來提升網站内容質量的主要因素。
二、解決思路
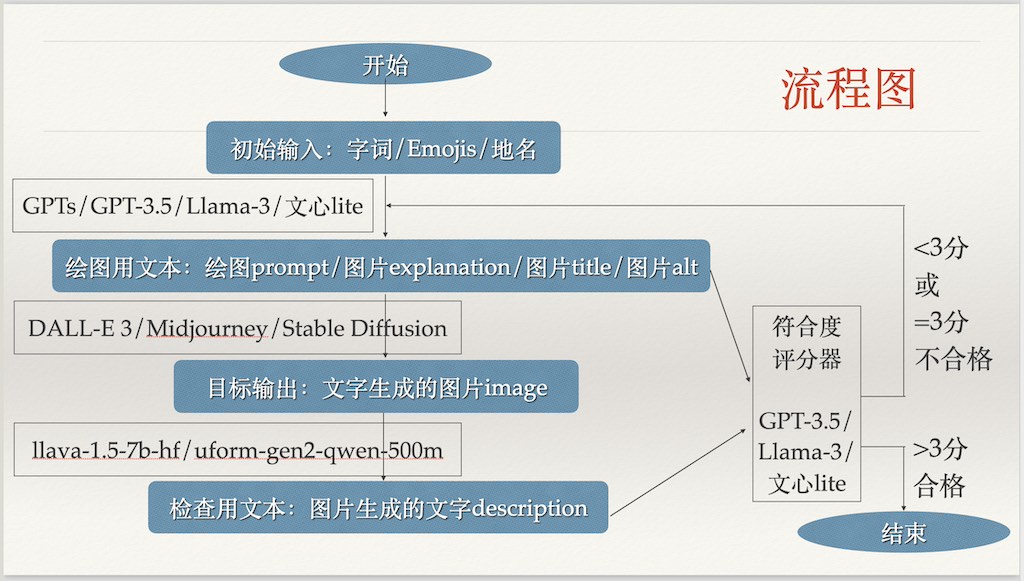
批量生成的圖片就用批量的辦法來做初步的質量檢查、篩選,然後還要再人工檢查,隻希望能夠降低人工檢查的工作量。
- 先使用文生圖模型從提示詞生成圖片;
- 需要使用圖生文模型API對已經生成的圖片寫出描述;
- 再使用大語言模型API對寫出的描述和原始繪圖提示詞進行對比打分;
- 不合格的重繪,合格的交給人工審核,希望機器審核合格後人工駁回得少。
流程圖如下:
三、模型選擇
生成圖片有兩種方式:ChatGPT+DALL-E的浏覽器自動化、批量調用Stable Diffusion的API,下面是第二種方式用到的模型:
- 文生文:可以使用GPT-3.5或者Llama-3-70B來生成繪圖提示詞prompt和圖片描述explanation;
- 文生圖:使用公司内帶GPU的機器上安裝的Stable Diffusion模型的API或者網上在線SD的API;
- 圖生文:嘗試了Cloudflare中提供的llava-1.5-7b-hf和uform-gen2-qwen-500m兩種生成description;
- 對比打分:用GPT-3.5或者Llama-3-70B來對繪圖前後的描述進行對比,或者對其它指标進行對比。
四、提示詞調試
各階段提示詞舉例:
圖生文llava-1.5-7b-hf:
export interface Env {
AI: Ai;
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const res: any = await fetch("https://cataas.com/cat");
const blob = await res.arrayBuffer();
const input = {
image: [...new Uint8Array(blob)],
prompt: "Generate a detailed description for this image",
max_tokens: 512,
};
const response = await env.AI.run(
"@cf/llava-hf/llava-1.5-7b-hf",
input
);
return new Response(JSON.stringify(response));
},
} satisfies ExportedHandler<Env>;圖生文uform-gen2-qwen-500m:
export interface Env {
AI: Ai;
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const res: any = await fetch("https://cataas.com/cat");
const blob = await res.arrayBuffer();
const input = {
image: [...new Uint8Array(blob)],
prompt: "Generate a detailed description for this image",
max_tokens: 512,
};
const response = await env.AI.run(
"@cf/unum/uform-gen2-qwen-500m",
input
);
return new Response(JSON.stringify(response));
},
} satisfies ExportedHandler<Env>;在本機批量調用的時候,圖片可以放置在本地,fetch的url可以用http://localhost開頭
文檔示範中的prompt: "Generate a caption for this image"生成的文字隻是一個圖片的标題,過于簡單,caption改為description後就是圖片的描述,再加上detailed又可以更詳細一些,但無論我再怎麼改提示詞,都沒有辦法生成更多細節描述了。
LLM評估explanation和description打分的system prompt:
There are two paragraphs below. The "explanation" field is the description of a picture when using text-to-image, and the "description" field is the picture description generated when using image-to-text. We are now going to evaluate the image quality of the text-to-image by comparing the contents of these two fields. Please carefully compare the protagonist, background, various details, style, feeling and other aspects of the two descriptions, and give a score of 0-5 points for each aspect (the higher the similarity, the higher the score, and the lower the similarity, the lower the score), and then give a comprehensive score of 0-5 points.
You should only output the json data like:
{
"final score": "3"
}
do not output other informaion.
輸入例子user prompt:
{
"explanation":"這幅插圖展現了一個人獨自坐在樹下,臉上帶著憂傷的表情,眼中含淚,象徵著悲傷和憂愁。背景色調暗淡,以傳達悲哀和悲痛的感覺。畫風仿傚傳統中國水墨畫,通過簡單而慎重的細節捕捉了“哀”字的本質。重點在於描繪悲傷和哀悼的情感,營造一種寧靜和內省的氛圍。",
"description":"The image portrays a somber scene set in a cemetery. A woman, dressed in a gray robe, sits on a stone bench under a large tree. The tree, with its twisted trunk and gnarled branches, is situated in the foreground, with its roots extending into the background. The woman, who is dressed in a long-sleeved shirt, is seated with her hands clasped together, her head bowed in a state of deep contemplation. The cemetery is filled with numerous gravestones, scattered across the landscape, and a fence can be seen in the distance. The foggy sky overhead adds to the atmosphere of the scene, creating a sense of solitude and quiet reflection."
}
LLM評估word和description打分的system prompt:
There are two paragraphs below. The "word" field is a word in the Chinese dictionary. We use text-to-image technology to generate a picture for it. The "description" field is the picture description generated when using image-to-text. We are now going to evaluate the picture quality of the text-to-image by comparing the contents of these two fields. Please carefully evaluate the protagonist, background, details, style, feeling and other aspects of the description, and then give a comprehensive score of 0-5 points (the more suitable the picture is for the word, the higher the score, and the less suitable the picture is for the word, the lower the score).
You should only output the json data like:
{
"final score": "3"
}
do not output other informaion.
輸入例子user prompt:
{
"word":"哀",
"description":"The image portrays a somber scene set in a cemetery. A woman, dressed in a gray robe, sits on a stone bench under a large tree. The tree, with its twisted trunk and gnarled branches, is situated in the foreground, with its roots extending into the background. The woman, who is dressed in a long-sleeved shirt, is seated with her hands clasped together, her head bowed in a state of deep contemplation. The cemetery is filled with numerous gravestones, scattered across the landscape, and a fence can be seen in the distance. The foggy sky overhead adds to the atmosphere of the scene, creating a sense of solitude and quiet reflection."
}
還把word加釋義一起來與description也進行對比打分,分數也差不太多。
下面是各種模型生成内容的對比表格,内容太多了,就放一個示意圖。

五、實踐情況
我們用800個圖片作為例子,批量運用圖生文API、批量LLM打分對比,然後再人工評估,将人工評估與自動打分進行對比。
人工評估的情況:
- 合格:644個
- 不合格:156個
機器評估的情況:
- 合格:600個,其中506個人工評估合格,94個人工評估不合格,機器錯判率:15.66%
- 不合格:200個,其中138個人工評估合格,62個人工評估不合格,機器錯判率:69%
從以上數據來看,機器評估與人工評估相差過大,準确率不足,難以實現我們預期的甄别效果。
六、結論及後續
目前還不能依靠自動化的辦法來進行大批量的生成圖片的質量檢查。主要原因在于文生圖和圖生文這兩個過程中信息失真過大,比較圖片生成前後的文字就難以得到準确的判斷。
後續可以進行的工作:
- 各階段提示詞的優化
- 自動化循環進行(目前用程序,以後是否用智能體)
- 更合适模型的選擇(國内免費模型)
- Lora訓練提升圖片合格率(這個是重點)
現階段無論文生圖、圖生文都還不能讓人滿意,而文生文基本上還是過關的,也許再過一年半載,文生圖、圖生文的質量大幅提升後,還是可以用批量方式實現質量檢查的。
评论