昨天刚写了一篇《不要误屏蔽百度MIP的爬虫》,顺着我们就继续检查其它站是否有被误屏蔽的事情,流量来源主要是百度的国内站可以看百度站长平台(百度搜索资源平台)里面的信息,流量来源主要是Google的国外站可以看Google Webmaster Tools (Google Search Console)。
今天同事发现一个台湾繁体版站的索引情况有异常:
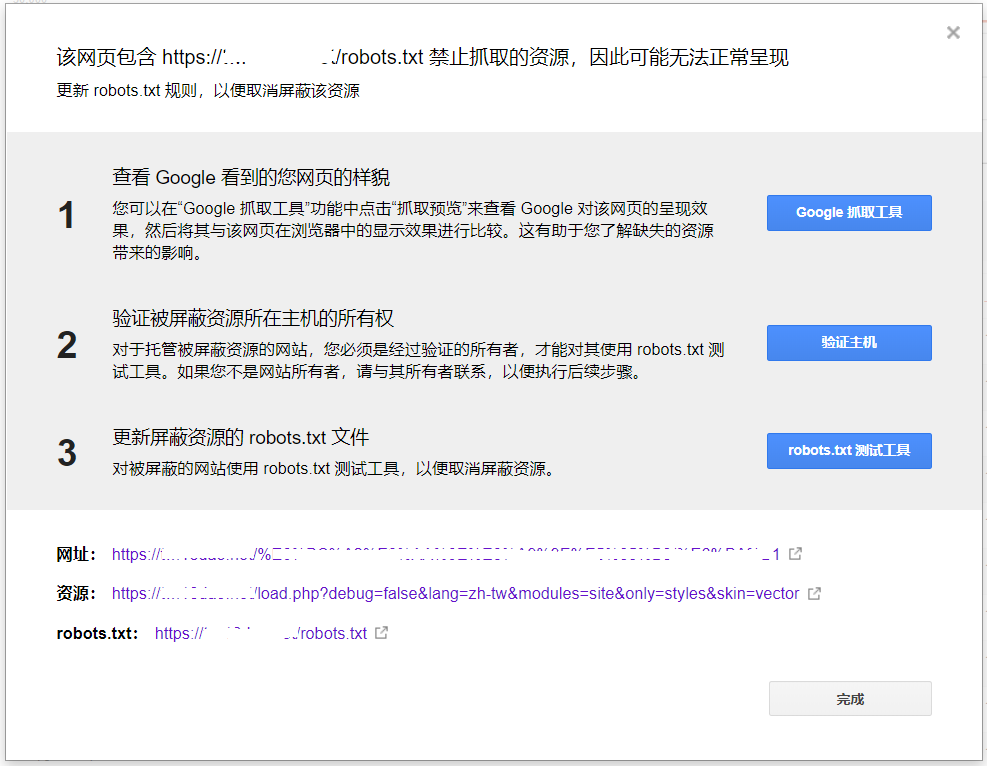
检查发现这个MediaWiki搭建的网站html中包含了load.php?这样的资源,而我们曾经在robots.txt里面禁止搜索引擎抓取load.php?这样的内容,这样的设置应该有好几年了,不知道为什么近期看到上面这样的提示。
我马上去修改robots.txt,去掉了对load.php的禁止:#Disallow: /load.php,再在Google Webmaster Tools里面用“Google抓取工具”和“robots.txt 测试工具”检测都没有问题。
Google官方说明:“禁止抓取的资源”报告 https://support.google.com/webmasters/answer/6153277
这里面说得还是很有道理的:
Googlebot 需要拥有对您网页上诸多资源的访问权限,才能以最佳效果呈现该网页并将其编入索引。例如,Googlebot 应该有权访问 JavaScript、CSS 和图片文件,以便能够像普通用户一样查看网页内容。 如果网站的 robots.txt 文件禁止 Google 抓取这些资源,则可能会影响 Google 对网页的呈现和索引编制效果,进而影响网页在 Google 搜索中的排名。
这个道理应该也适用于百度等其它搜索引擎,我再去检查其它MediaWiki以及Drupal网站看看,不仅html网页不能屏蔽搜索引擎,里面的js/css/图片等也不能屏蔽搜索引擎。
不可小看了这个问题,如果误屏蔽了搜索引擎,可能会导致流量大幅下降。
补充:页面中我们自己站的资源可以控制允许搜索引擎爬虫来抓取,但页面中嵌入的其它站的资源(例如Google AdSense、百度联盟广告等)我们还没有办法控制是否允许搜索引擎爬虫抓取,那暂时还没有办法。
自由标签
评论3
wsjyj.hhjy.net,蓝金融办卡,这个网站怎么优化
wsjyj.hhjy.net,蓝金融办卡,这个网站怎么优化这好像是推广单页类似的吧,我没有做过这种
这好像是推广单页类似的吧,我没有做过这种,不过网上讲这种操作办法的文章有很多,你可以搜索看看
我禁止了go.php的爬取
我禁止了go.php的爬取,因为这个文件仅仅是个外链跳转的时候用的,我发现有人再利用这个跳转进行恶意的跳转,所以就给禁止了,具体有啥影响目前还不是很清楚,先观察一下看看谷歌会不会有错误提示!