最近几天我们国内的两个网站都遇到访问困难,检查发现是百度爬虫抓取量大增,是以前正常情况的很多倍,导致Web服务器CPU、带宽以及数据库服务器都难以应付。Googlebot也曾经出现类似情况。
办法一(站长平台设置):
按照以前的办法,我们是在百度资源平台或者Google Search Console中设置降低爬虫的抓取速率,不过这样设置后需要等待2-3天时间生效,而不能解决当时的问题。
这是 爬虫 分类的页面,点击下面标题查看详细文章内容:
最近几天我们国内的两个网站都遇到访问困难,检查发现是百度爬虫抓取量大增,是以前正常情况的很多倍,导致Web服务器CPU、带宽以及数据库服务器都难以应付。Googlebot也曾经出现类似情况。
按照以前的办法,我们是在百度资源平台或者Google Search Console中设置降低爬虫的抓取速率,不过这样设置后需要等待2-3天时间生效,而不能解决当时的问题。
最近几天我们有两个域名下的网站从Google Analytics看流量异常增高,是平时的数十倍,同时在线人数也是以前的几十倍,从流量来源看主要是直接来源用户大量增加,这显然是不正常的。截图如下:
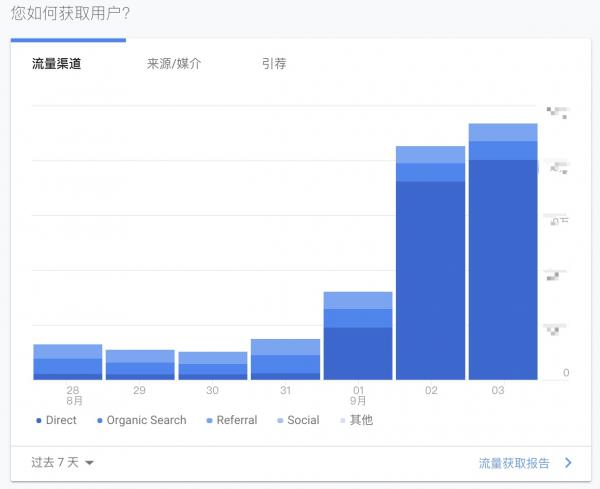
从相同网站的百度统计、Google AdSense数据来看却没有明显变化,只是Google Analytics
标明访问者属性的User Agent是可以由软件进行修改的,所以有很多采集者为了防止自己被屏蔽,就把User Agent改为搜索引擎爬虫的特征,例如:
我们很早前就开始做百度MIP版本页面了,通过这种方式也获得了流量的增长和比较好的用户体验。但最近流量不太稳定,有的站MIP流量曾经很高,但后来跌落很厉害。还有的站MIP流量下降后,对应的普通WEB版流量上升。
我们做了各种推测和试验,今天发现了一条重要线索:百度的MIP爬虫曾经被我们屏蔽。
按照百度官方的说法,其MIP爬虫的User Agent是这样的:
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Geck
最近新增了一些网站内容,结果正常的访问者还没有开始来,采集的爬虫就来了,真像是嗜血的鲨鱼,发现哪里有美味马上就盯上了😰。
近期也看了一些关于反采集的文章,世上没有完美、一劳永逸的反采集办法,成了与采集者的对峙,双方不断变换对抗办法,成了一种体力活。
我们现在也不得不采取更严格的反采集措施,看到很多采集IP都来自amazon云计算,这就可以用hostname反查来进行屏蔽,以前曾经做过测试,今天再次测试并记录。
在apache的httpd.conf文件中添加一行:
HostnameLoo
我们在采用《使用Apache模块mod_qos反采集》的办法以后,确实有一些效果,但从apache报错日志中看到也有百度、Google等搜索引擎的IP被屏蔽了,现在来收集整理一下常见搜索引擎的IP地址段,以便加入白名单中:
Googlebot:
Baiduspider:
我们一些大数据量的网站总是沦为爬虫获取信息的对象,导致大量消耗服务器资源。有些爬虫是为了采集整个网页,也有些只来找寻邮箱等联系方式信息。
前段时间发现有一阵爬虫特别多,从apache日志里面看到这样的特征:
115.151.110.238 - - [14/Jul/2018:18:03:01 +0800] port:443 "liaoning.mingluji.com" "GET /%E5%AE%89%E5%BE%BD%E5%A5%BD%E6%80%9D%E5%AE%B6%E6%B6%82%E6%96%9
自从做网站以来,大量自动抓取我们内容的爬虫一直是个问题,防范采集是个长期任务,这篇是我5年前的博客文章:《Apache中设置屏蔽IP地址和URL网址来禁止采集》,另外,还可以识别User Agent来辨别和屏蔽一些采集者,在Apache中设置的代码例子如下:
RewriteCond %{HTTP_USER_AGENT} ^(.*)(DTS\sAgent|Creative\sAutoUpdate|HTTrack|YisouSpider|SemrushBot)(.*)$
RewriteRule .* - [F,L]
屏蔽User
以前托管服务器或者租用的服务器一般都是100M共享的带宽,很少出现机器带宽被占满的情况,去年开始采用阿里云平台后,带宽就是一个不得不考虑的成本因素,我们一般都是每台ECS购买的10M左右带宽,每年费用已经不少了,而投入使用后很轻易就会被占满,关键是网站的流量并没有特别提升,广告收入没有增加,成本却在大幅提高,还导致正常用户访问变慢、困难。
同事在Linux服务器上安装了一个iftop来查看带宽占用情况,很容易就发现了是搜索引擎的爬虫抓取sitemap.xml这样的网址占用了很大带宽,我们网站系列多、页面多、还有多语言或者手机版,网站地图就特别的多,如果爬虫来得

网站内容抓取采集真是中国互联网的一大特色,我们做了这么多年网站,一直都遇到各种各样对我们内容进行采集、复制的家伙。前一阵子发现一个网站 www.postcodequery.com 具体和我们的 www.postcodebas
2002-2023 v11.7 a-j-e-0